
1. Einleitung
Indirekt erhobenen Daten sagt man oft nach, dass sich deren sprachwissenschaftliche Verwertbarkeit nur auf die lexikalische Ebene der Sprache beschränkt. Dass es aber Strategien gibt, mit Hilfe derer man die Sprachbelege auch in einer phonetisch-phonologischen Sicht interpretieren kann, soll dieser Beitrag zeigen.
Dazu findet zunächst eine Gegenüberstellung direkter und indirekter Erhebungsmethoden statt. Als eine moderne Form der indirekten Erhebung kann das Crowdsourcing gelten, das hier am Beispiel des Forschungsprojekts VerbaAlpina herangezogen werden soll. Anhand der im Projekt erhobenen Sprachdaten wird gezeigt, dass es für eine erweiterte Interpretation der Daten zielführend ist, sich in die Position eines Laien zu begeben, der mithilfe eines begrenzten Zeichensatzes Laute abbilden möchte, für das das herkömmliche Alphabet kein Graphem bereithält.
2. Erhebung von Sprachdaten
Sprachdaten können im Wesentlichen auf zwei Arten erhoben werden: durch direkte oder indirekte Erhebungen. Als Darstellungsinstrument der Sprachdaten, die meist mit Blick auf geographische Unterschiede erhoben werden, dienen in Sprachatlanten gebündelte Sprachkarten. Im Folgenden sollen die beiden Erhebungsmethoden nun zunächst kurz vorgestellt werden.
2.1. Direkte Erhebungen
Bei der direkten Erhebung handelt es sich um eine mündliche Befragungsform, die die Erhebung gesprochener Sprache zum Ziel hat. Der Explorator richtet seine Fragen dabei mündlich an die Informanten und schreibt die Antworten dazu selbst mit oder nimmt diese auf Tonträger auf. Informant und Explorator sind während der Befragung zur selben Zeit am selben Ort, meist bei den Informanten zuhause (Kunzmann/Mutter 2020, 33; Seiler 2010, 514).
Direkte Erhebungen sind typisch für die romanische Tradition (Seiler 2010, 515). Als Instrument der Darstellung der erhobenen Sprachdaten werden sogenannte analytische Karten bzw. Belegkarten gewählt. Charakteristisch für diese Karten ist die Präsentation von Einzelbelegen, d.h. die Belege jedes Erhebungsortes werden abgebildet und es findet keine Typisierung statt. Diese Darstellungsform hat den Vorteil, dass sie quellentreu und damit nachvollziehbar und überprüfbar ist. Andererseits sind analytische Karten jedoch vergleichsweise unübersichtlich (Lücke 2019).
Diese Erhebungsmethode eignet sich besonders für Phänomene, die indirekt nicht oder schwer zu erheben sind, u.a. Phänomene aus den Bereichen Phonetik, Phonologie und Prosodik (SyHD).
2.1.1. Vor- und Nachteile direkter Erhebungen
Die direkte und damit unmittelbare Erhebung von Sprachdaten bringt einige Vorteile mit sich. So kann der Explorator, dadurch dass er bei der Befragung vor Ort ist, dem Informanten bei Schwierigkeiten Hilfestellung geben oder bei Verständnisproblemen gezielt nachfragen. Ebenso hat der Explorator die Möglichkeit, Kommentare und Reaktionen des Informanten zu vermerken, die für die Interpretation der Sprachdaten hilfreich sein könnten und kann lautliche Feinheiten in Lautschrift eindeutig festhalten. Die direkte Methode bietet zudem die Möglichkeit zum Einsatz von Ton, bewegtem Bild oder Spielen.
Einer der größten Nachteile dieser Erhebungsmethode ist jedoch, dass sie mit einem relativ hohen finanziellen, personellen sowie zeitlichen Aufwand verbunden ist. So müssen zur Befragung zunächst geeignete Informanten gesucht und Einzelgespräche mit ihnen vereinbart und durchgeführt werden. Da die Befragung bei den Informanten zuhause stattfindet, fallen auch meist erhebliche Reisekosten für die Reisen ins Untersuchungsgebiet an. Darüber hinaus besteht die Gefahr des sogenannten Beobachterparadoxon, d.h. dass der Informant aufgrund der Anwesenheit eines Beobachters in Form des Explorators in seiner natürlichen Sprache beeinflusst wird. Ebenso kann es zu Interferenzen mit der Standardsprache kommen, wenn der Explorator in Standardsprache und der Informant in Dialekt spricht (Kunzmann/Mutter 2020, 33; SyHD).
2.1.2. Beispiele
Das erste und auch prominenteste Beispiel für direkte Erhebungen ist der französische Sprachatlas Atlas linguistique de la France (ALF) von Jules Gilliéron und Edmond Edmont. Zwischen 1897 und 1901 führte Edmond Edmont dazu Erhebungen in 638 Gemeinden in Frankreich durch. Dafür benutzte er einen Fragebogen, der sich aus Begriffen zusammensetzte, zu denen er 735 Informanten befragte. Die gesammelten Dialektdaten wurden dann in Form von Karten mit insgesamt 639 Erhebungspunkten veröffentlicht. Neben oder unter der Nummer des jeweiligen Erhebungspunktes erscheint immer die mit dem phonetischen Rousselot-Gilliéron-Alphabet transkribierte dialektale Antwort. Insgesamt wurden 1920 Karten (1421 Vollkarten, 326 Halbkarten und 173 Viertelkarten) alphabetisch nach Konzepten geordnet und zwischen 1902 und 1910 zunächst als Faszikel und dann als Bände veröffentlicht (ALF).
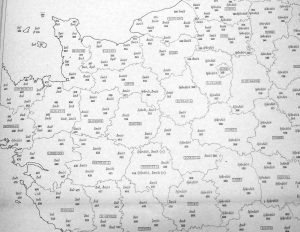
Beispiel aus dem ALF: Kartenausschnitt der Karte Aujourd'hui (Wikipedia)
Ein weiteres bekanntes Beispiel für einen durch direkte Erhebung entstandenen Sprachatlas ist der Sprach- und Sachatlas Italiens und der Südschweiz (AIS) von Karl Jaberg und Jakob Jud (1928-1940). Hier wurden auf insgesamt 1681 Karten und 20 Konjugationstabellen die Dialekte von 416 Orten erfasst. Die direkte Befragung wurde mithilfe eines Fragebuchs durchgeführt (Krefeld 2019g).
2.2. Indirekte Erhebungen
Die indirekte Erhebung von Sprachdaten erfolgt in Form einer schriftlichen Befragung mit Hilfe eines Fragebogens, der den gewünschten Informanten per Post zugesandt oder digital zur Verfügung gestellt wird. Anders als bei der direkten Erhebung sind Informant und Explorator während der Befragung räumlich und zeitlich voneinander getrennt (Seiler 2010, 514; Kunzmann/Mutter 2020, 33/34).
Indirekte Erhebungen sind typisch für die germanische Tradition (Seiler 2010, 515). Zur Darstellung der erhobenen Sprachdaten werden sogenannte synthetische Karten bzw. Punktsymbolkarten verwendet. Anders als bei analytischen Karten werden Einzelbelege hier nur vereinzelt dokumentiert. Stattdessen werden diese nach unterschiedlichen Kategorien typisiert und pro Typ erscheint ein Symbol auf der Karte. Dies hat den Vorteil, dass die Karten einerseits verhältnismäßig übersichtlich, auf der anderen Seite aber auch schwer überprüfbar sind (Lücke 2019).
Diese Erhebungsmethode erweist sich als besonders geeignet für lexikalische und (morpho-) syntaktische Fragestellungen, da hier vor allem die Vorteile dieser Erhebungsmethode im Vordergrund stehen (Eichhoff 1982, 550; SyHD).
2.2.1. Vor- und Nachteile indirekter Erhebungen
Im Vergleich zur direkten Erhebungsmethode besteht ein großer Vorteil dieses Verfahrens darin, dass die Informanten die Fragen in Ruhe beantworten können, ohne durch die Präsenz des Explorators oder eines Mikrofons in ihren Aussagen beeinflusst zu werden, wodurch das Beobachterparadoxon bei dieser Erhebungsmethode nicht zum Tragen kommt. Darüber hinaus sind indirekte Erhebungen vergleichsweise kostengünstig und erfordern einen geringeren personellen und zeitlichen Aufwand. Deshalb können mit dieser Methode auch größere Erhebungsgebiete so gut wie lückenlos mit Belegorten versehen werden.
Neben all den Punkten, die für indirekte Erhebungen sprechen, bringt dieses Verfahren aber auch einige Nachteile mit sich, die vor allem mit der Abwesenheit des Explorators während der Befragung verbunden sind. So kann der Explorator aufgrund der räumlichen Trennung vom Informanten bei schwierigen Fragen zum Beispiel keine Hilfe leisten und der Informant hat keine Möglichkeit zur Rückfrage. Ebenso kann die Formulierung der Fragen anders als bei direkten Erhebungen nicht mehr an eventuelle Erkenntnisse, die während der Befragung gewonnen wurden, angepasst werden und auch die Anzahl der Fragen, die ein Informant selbstständig bereit ist zu beantworten, ist nicht so groß wie wenn ein Explorator sie vor Ort stellen könnte. Zudem hat der Explorator keine Kontrolle über die Erhebungssituation und kann nicht sicherstellen, dass der Informant den Fragebogen selbstständig und nicht gemeinsam, z.B. mit dem/r Partner/in, und mit der nötigen Sorgfalt ausfüllt. Ebenso wenig können Kommentare oder Reaktionen der Informanten wie zögerliches Antworten, welche für die Interpretation von Daten von Bedeutung sein können, erfasst werden. Da die Verschriftlichung der Antworten von Seiten der Informanten in der Regel in „Laienschreibung“, d.h. nur mit Hilfe des gewöhnlichen Alphabets, erfolgt, können gesprochene Laute oftmals auch nicht exakt wiedergegeben werden (Eichhoff 1982, 550; Kunzmann/Mutter 2020, 33/34).
2.2.2. Beispiele
Die ersten und wohl bekanntesten indirekten Erhebungen stellen die von Georg Wenker dar (1876-1887), die auch die Grundlage für den Deutschen Sprachatlas (DSA) bildeten. Unter Leitung Wenkers wurden dazu fast 50.000 Fragebögen an Volksschullehrer aus insgesamt 40.736 Schulorten im gesamten Deutschen Reich versandt. Der Fragebogen beinhaltete 42 Sätze auf Hochdeutsch, die die Lehrer in gewöhnlichem Alphabet in den von ihnen gesprochenen Ortsdialekt übertragen sollten. Die Erhebung erfolgte in mehreren Phasen: von April 1876 bis im Frühjahr 1877 wurden die Wenkerbögen zunächst in die Schulorte der Rheinprovinz nördlich der Mosel versandt. Im Jahr 1877 wurden Daten in ganz Westfalen erhoben und zwischen 1879 und 1880 wurden Sprachdaten in Nord- und Mitteldeutschland erfasst. Der Vergleichbarkeit der Ergebnisse wegen, wurde 1884 der Fragebogen, der bei der Erhebung in Nord- und Mitteldeutschland zum Einsatz kam, in das rheinische Gebiet versandt. 1887 wurde schließlich Süddeutschland erfasst. Die Erhebungen Wenkers umfassen insgesamt 1668 Karten (REDE).
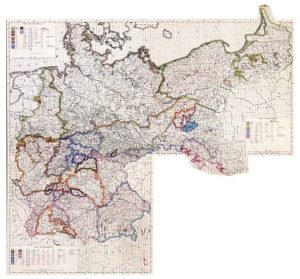
Beispiel aus Wenker: Karte Bäumchen (REDE)
Als weitere Beispiele für indirekte Erhebungen sind diverse Dialektwörterbücher zu nennen, so z.B. das Wörterbuch des Brandenburg-Berlinischen Spracharchivs (BBSA), das Wörterbuch der bairischen Mundarten in Österreich (WBÖ) sowie das Bayerische Wörterbuch (BWB) (Kunzmann/Mutter 2020, 34).
2.2.3. Crowdsourcing
Während indirekte Erhebungen traditionell durch das Aussenden von Fragebögen erfolgten (siehe 2.2.), bietet sich dank des Internets heutzutage eine neue webbasierte Möglichkeit zur indirekten Datenerhebung in Form von Crowdsourcing (Kunzmann/Mutter 2020, 32). Dabei wird eine bestimmte Aufgabe von einer Gruppe von Crowdern, d.h. von einer anonymen Gruppe von Menschen aus der Crowd, gelöst. Crowdsourcing hat dabei meist die Gestalt einer Online-Befragung. Anders als bei der klassischen Online-Befragung, wo zwischen verschiedenen vorgegebenen Antwortmöglichkeiten gewählt werden kann, können diese beim Crowdsourcing von den Teilnehmern jedoch auch selbst eingebracht bzw. ausgewählt werden. Dabei wird v.a. auf die Leistung des Kollektivs gesetzt, das meist, aber nicht ausschließlich, aus Laien besteht (Juska-Bacher/Biemann/Quasthoff 2014, 14).
3. Crowdsourcing bei VerbaAlpina
Das Projekt VerbaAlpina, das den Alpenraum in seiner kultur- und sprachgeschichtlichen Zusammengehörigkeit untersucht, bezieht sein Datenmaterial aus verschiedenen Quellen. Der Großteil des Sprachmaterials, das im Rahmen des Projekts zusammengetragen und analysiert wird, stammt aus georeferenzierten Sprachatlanten und Wörterbüchern. Diese decken den Alpenraum jedoch oft nicht vollständig ab und variieren zudem teils stark hinsichtlich ihrer Entstehungszeit und der dokumentierten Begriffe. So entsteht deshalb ein zunächst heterogener Datenbestand. Um die bestehenden Lücken und Inkonsistenzen der genannten Quellen auszugleichen, werden bei VerbaAlpina Sprachdaten zusätzlich in Form von Crowdsourcing erhoben.
3.1. Konzeption
Für das Crowdsourcing hat VerbaAlpina ein speziell dafür konzipiertes Internetportal entwickelt, über das die Crowder, d.h. im Fall von VerbaAlpina alle interessierten Dialektsprecher im Alpenraum, die Möglichkeit haben, an der großen Online-Befragung teilzunehmen. Mittels eines Text-Stimulus auf Standarddeutsch, und wenn vorhanden, dem dazu passenden Bild, wird hier dialektale Lexik erhoben. Dabei dreht sich alles um eine zentrale Frage: „Wie sagt man zu ,Begriff‘ in ,Gemeinde‘?“. Jeder Sprecher muss also zunächst eine Gemeinde auswählen, für die Eintragungen gemacht werden sollen. Anschließend kann aus einer Liste an standarddeutschen Begriffen aus den Wortschatzbereichen „Almwirtschaft“, „Natur“ und „modernes Leben“ der Begriff ausgewählt werden, zu dem der entsprechende Dialektbegriff eingetragen werden soll. Zusätzlich zu dem jeweiligen Dialektwort können die Crowder auch Kommentare, z.B. zur Herkunft oder zur Verbreitung der jeweiligen Wörter, hinterlassen sowie neue Konzepte vorschlagen, die bislang noch nicht in der Liste der zur Auswahl stehenden Begriffe erscheinen. Sobald eine Eintragung gemacht wurde, ist diese auf der Karte sofort für alle Nutzer sichtbar und eigene Beiträge können so mit den Eintragungen anderer verglichen werden. Hinsichtlich der Verschriftung der Einträge werden dem Crowder dabei keinerlei Vorgaben gemacht, d.h. die Transkription erfolgt über das geläufige Alphabet nach eigenem Ermessen. Dabei wird auch eine überschaubare Menge an Metadaten gesammelt, wie der zugehörige Ort zum Beleg (Auskunft des Informanten), der Zeitpunkt der Eintragung sowie zu Beginn der Befragung die Dialektbezeichnung, die aus einer Liste gewählt werden kann. Bei einer Registrierung ist zusätzlich die Angabe einer E-Mail-Adresse notwendig. Metadaten wie Name, Alter, Geschlecht, Ausbildung usw. werden nicht erhoben.
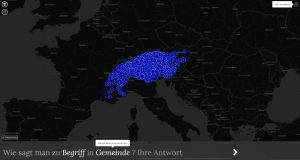
Crowdsourcing-Oberfläche von VerbaAlpina. Die blauen Kreise zeigen die Eintragungen der einzelnen Nutzer. (VerbaAlpina)
3.2. Durchführung
Für erfolgreiches Crowdsourcing bedarf es neben der Konzeption einer entsprechenden Oberfläche zur Durchführung der Online-Befragung zusätzlich einer zielgruppenorientierten Akquirierung von Sprechern, im Fall von VerbaAlpina von Dialektsprechern aus dem Alpenraum, die an der Online-Befragung teilnehmen. Im Rahmen von VerbaAlpina wurden dazu in den ersten beiden Projektphasen (Phase I: 10/2014-10/2017; Phase II: 11/2017-10/2020) zunächst entsprechende Zielgruppen definiert1. In Projektphase I, in der der Wortschatz rund um Almwirtschaft und Milchverarbeitung im Zentrum stand, wurde dabei zwischen den folgenden Kategorien unterschieden:
Gewerbe
- Käsereien
- Molkereien
- Almen
Kultur
- Vereine (z.B. Almwirtschaftlicher Verein Oberbayern (AVO), Alpwirtschaftlicher Verein im Allgäu e.V. (AVA)
- Museen (z.B. Museum Glentleiten)
Ausbildung
- Berufsschulen und sonstige Ausbildungsstätten
Portale
- Fachportale der Milchbranche (wie z.B. z’alp.ch)
Medien
- Zeitschriften aus dem Bereich Almwirtschaft/Milchverarbeitung (z.B. „Deutsche Molkereizeitung“, „Der Almbauer“)
- (Online-) Zeitungen
- Fernsehen
- Radio
- Verteiler
- Social Media: Facebook + Twitter
Private Kontakte
In der zweiten Projektphase, in der der Wortschatzbereich Natur im Mittelpunkt stand, d.h. Begriffe aus den Bereichen Flora, Fauna, Landschaftsformationen und Wetter, wurden die bereits existenten Kategorien aus Projektphase I noch um die Kategorien „Nationalpark/Forst“, „Wetterdienste“ und „Politik/Organisation“ erweitert. Zudem kam im Bereich Social Media neben Facebook und Twitter im Jahr 2020 auch noch Instagram hinzu.
Als Auswahlkriterium der einzelnen Kontakte je Kategorie galt, dass sie eine thematische Zugehörigkeit zu den Wortschatzbereichen aufwiesen, die in der jeweiligen Projektphase im Mittelpunkt standen, und dass sie im Untersuchungsgebiet von VerbaAlpina lagen. Neben einem entsprechenden Anschreiben und einem vorgefertigten Newsletter-Text wurde zudem ein spezieller Flyer und ein Pressetext zum Bewerben des Crowdsourcings entworfen. Da das Untersuchungsgebiet von VerbaAlpina länderübergreifend ist und die Sprachen Deutsch, Italienisch, Französisch, Slowenisch, Rätoromanisch sowie die jeweiligen Dialekte der Sprachen umfasst, wurden auch die für das Crowdsourcing benötigten Materialien mehrsprachig verfasst. Der Pressetext erschien auf Deutsch, Italienisch und Französisch, der Flyer zudem auch noch auf Slowenisch. Sowohl Flyer als auch Pressetext sind mittlerweile in der dritten Auflage erschienen.

Crowdsourcing-Flyer Deutsch, 1. Auflage

Crowdsourcing-Flyer Deutsch, 2. Auflage

Crowdsourcing-Flyer Deutsch, 3. Auflage
Die konkrete Kontaktaufnahme mit den Kontakten, die von VerbaAlpina für die oben genannten Kategorien in der Projektdatenbank zusammengetragen wurden, wurde dann wie folgt durchgeführt. Die einzelnen Kontakte wurden zunächst per E-Mail, teils auch telefonisch, kontaktiert, mit der Bitte, an der Sprecherbefragung teilzunehmen. Ebenso wurde angefragt, ob über einen bestehenden Verteiler durch Versand des von VerbaAlpina entworfenen Newsletter-Texts auf die Sprecherbefragung aufmerksam gemacht werden kann. An Schulen und Museen wurden nach Kontaktaufnahme zudem Flyer und Poster verschickt. Zeitschriften und Zeitungen erhielten den von VerbaAlpina verfassten Pressetext als Textvorlage für einen möglichen Beitrag über das Projekt. Bisher sind insgesamt 24 Textbeiträge über VerbaAlpina in Zeitungen, Zeitschriften und auf Portalen aus dem Alpenraum erschienen. Darüber hinaus wurde über die Social-Media-Accounts von VerbaAlpina in regelmäßigen Abständen auf die Sprecherbefragung hingewiesen. Auf Facebook wurden zusätzlich zu Posts auf der eigenen Facebook-Seite von VerbaAlpina auch Posts auf Seiten entsprechender Gruppen und Vereine verfasst, die Teil der Zielgruppe waren. Bei diversen Vereinen konnte das Projekt im Rahmen von Tagungen (Alpsennenkurs, Almehrkurs, Almbauerntag) den anwesenden Vereinsmitgliedern vorgestellt werden. Zudem wurde im Rahmen der Dialekt-Themenwoche des Bayerischen Rundfunks vom 27.04.18 bis 04.05.18 sowie im Rahmen von drei Interviews mit Mitarbeitern von VerbaAlpina auf BR Heimat, Radio Regenbogen und im ORF über die Sprecherbefragung von VerbaAlpina berichtet.
Um die Crowd möglichst langfristig zu binden und die Sprecherbeteiligung möglichst fortwährend und mehr oder weniger konstant hoch zu halten, hat sich VerbaAlpina mehrere motivationsfördernde Maßnahmen überlegt. Zum einen werden vor allem die Social-Media-Kanäle dazu genutzt, um durch entsprechende Posts immer wieder auf neue Features im Crowdsourcing-Tool und auf den aktuellen Stand der bislang durch Crowdsourcing gesammelten Dialektbelege hinzuweisen. Zudem gibt es im Crowdsourcing-Tool die Möglichkeit zur Registrierung. Registrierte Nutzer werden in regelmäßigen Abständen per E-Mail kontaktiert und immer wieder zur Teilnahme an der Sprecherbefragung angeregt. Außerdem verfügt das Crowdsourcing-Tool über eine Bestenliste, in der neben den beliebtesten Konzepten auch die aktivsten registrierten User und die aktivsten Gemeinden gelistet sind. Die aktivsten User erhalten per E-Mail eine Urkunde und werden zum Champion gekürt.
3.3. Resonanz
Die Erfahrungen der mittlerweile über drei Jahre, in denen das Crowdsourcing nun bei VerbaAlpina zum Einsatz kommt, haben in erster Linie gezeigt, dass diese Datenerhebungsmethode kein Selbstläufer ist. Vielmehr ist Crowdsourcing erst dann richtig erfolgreich, wenn es regelmäßig und aktiv durch gezielte Aktionen beworben wird. So zeigt die von VerbaAlpina erhobene Statistik der Crowd-Aktivitäten, dass die Sprecherbeteiligung vor allem dann ansteigt, wenn die Online-Befragung unmittelbar davor in irgendeiner Form beworben worden ist. Die unter 4.2. bereits genannten Maßnahmen, die zu diesem Zwecke bislang unternommen wurden, variieren in Ertrag und Reichweite jedoch teils stark. Den größten Ertrag und die größte Reichweite haben demnach Projektberichte, die online veröffentlicht werden, sei es auf Websites von Radiosendern, Zeitungen, Portalen oder auf Social Media, z.B. in Form von Posts in Facebook-Gruppen, in denen die Gruppenmitglieder zur Teilnahme am Crowdsourcing aufgerufen werden. Im Vergleich zu analogen Medien gibt es hier den Vorteil, dass die Leser über einen im jeweiligen Beitrag erwähnten Link direkt zum Crowdsourcing von VerbaAlpina weitergeleitet werden, ohne davor das Medium wechseln zu müssen. Den geringsten Erfolg hatten bislang hingegen Radiointerviews und populärwissenschaftliche Vorträge.
Insgesamt haben bisher 1318 Crowder am Crowdsourcing von VerbaAlpina teilgenommen und bislang 20360 Dialektwörter (siehe Abb. 7) beigesteuert. Dabei ist bemerkenswert, dass ca. 50 % der gesamten Belege von rund nur 10 % der Crowder stammt (Stand: 09/2018). Das bedeutet im Umkehrschluss, dass es zwar viele Informanten gibt, die meisten von ihnen aber nur wenige Belege liefern (Median = 5). Die
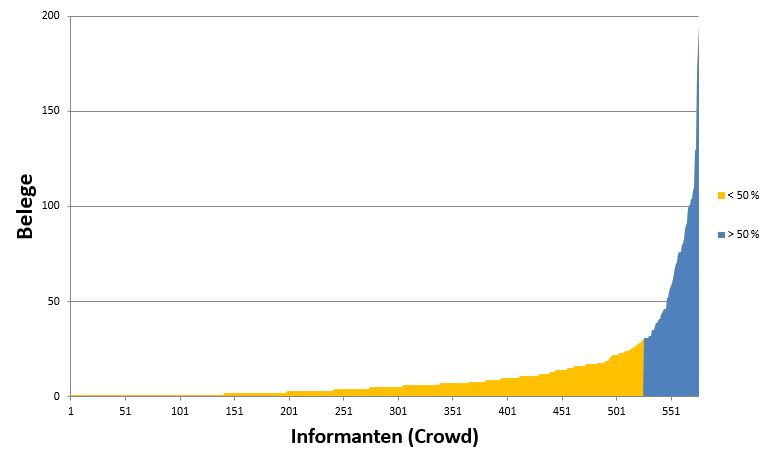
Anzahl der Belege pro Crowder, aufsteigend (Stand 08/2018).
folgende Grafik veranschaulicht dies als Säulendiagramm, das den Informanten (x-Achse) die Anzahl der Belege (y-Achse) zuordnet. Die Informanten wurden aufsteigend nach der Anzahl ihrer Belege angeordnet.
Ebenso tragen die einzelnen Staaten, die Teil des Untersuchungsgebiets sind, zu unterschiedlichen Anteilen zur Gesamtzahl der Belege bei. So stammt fast die Hälfte der Belege aus Italien, hierzu zählen jedoch auch die deutschsprachigen Belege aus Südtirol. Etwas mehr als ein Viertel der Belege stammen aus Deutschland und fast ein Sechstel aus der Schweiz. Frankreich liegt mit 205 Belegen dagegen auf dem vorletzten Platz vor Liechtenstein.
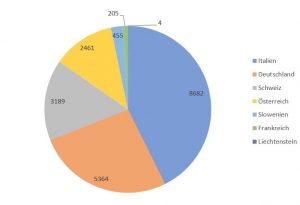
Beleganzahl nach Staaten
4. Die Kreativität der „Schreibgemeinschaft“
Für sprachwissenschaftliche Untersuchungen, die sich mit der Variation auf lexikalischer Ebene befassen, stellt indirekt erhobenes Sprachmaterial nach wie vor eine geeignete Datengrundlage dar. Der Zeichensatz, beispielsweise das deutsche Alphabet, lässt im Großteil der Fälle von laienverschrifteten Wortformen kaum Zweifel, welchem Worttypus der jeweilige Beleg angehört. Eindeutiger sind Erhebungsverfahren mit vorgefertigten Listen, die bereits ein festes Repertoire an lexikalischen Formen anbieten und aus denen der Informant wählen kann. Diese Methode birgt freilich Gefahren im Hinblick auf die Qualität der Daten. So kann die Reihenfolge der gelisteten Wortformen eine Rolle bei der Wahl derselben spielen, Störfaktoren wie Primär- (vgl. American Psychological Asscociation 2020) oder Rezenzeffekte (vgl. American Psychological Asscociation 2020b) könnten dabei das Ergebnis verfälschen. Darüber hinaus muss man in Betracht ziehen, dass Wortformen, die im Dialekt zwar gebraucht, in der angebotenen Wortsammlung aber nicht gelistet sind, übersehen werden.
Weitaus schwieriger gestaltet sich die Verwertung indirekt erhobenen Sprachmaterials für phonetische Untersuchungen. Zwar ist durch die Phonem-Graphem-Beziehung eine gewisse Eindeutigkeit gegeben, welches Schriftzeichen für welche Gruppe von Lauten stehen kann, dies sagt jedoch nichts über den genauen Lautcharakter, also über das Phon selbst aus. Das zeigt beispielsweise schon ein standarddeutsches Wort wie geben, in dem das Phonem /e/ innerhalb desselben Wortes dem Phon [e], [ə] bis hin zu einem totalen Ausfall des Segments entsprechen kann. Dies kann auch bei einem Phonem innerhalb zweier Varietäten der Fall sein. So lässt sich anhand der Schreibung von Gipfel nichts darüber aussagen, ob sich die Aussprache mehr an einem bundesdeutschen oder einem österreichischen Gebrauchsstandard (/i/ in Gipfel: [ɪ] bundesdeutsch, [i] österreichisch) orientiert (vgl. Kleiner 2019).
Mit dem Problem, einem Laut einen geeigneten Buchstaben zuzuordnen, sahen sich auch diejenigen konfrontiert, die als erstes versuchten, ihre Form ihres gesprochenen Deutsch schriftlich zu fixieren, die Mönche. Diese, deren Alphabetisierung in Latein stattfand, warn im ersten Jahrtausend nach Christus mit der Herausforderung konfrontiert, ihr eigenes volkssprachliches Idiom in das Korsett des lateinischen Alphabets zu fassen (vgl. Schmid 2017, 58). So wurde der Frikativ [x] im Althochdeutschen meist durch Digrapheme <hh> oder – wie heute noch der Fall – als <ch> verschriftet. Dass hierfür aber auch Schreibungen wie <hc> zu finden sind, zeigt, dass die Wahl und die Reihenfolge der einzelnen Lettern des Digraphems eine untergeordnete Rolle spielten und es also wirklich primär darum ging, eine Zeichenkombination für den Laut zu etablieren (vgl. Schmid 2017, 81). Die heutige deutsche Schriftsprache weist noch weitere Multigrapheme auf, die auf den ersten Blick nicht als solche offenbar sind, wie beispielsweise <ng> für [ŋ]. Der sehr frequente Trigraph <sch> stellt insofern eine Besonderheit dar, als dass sich hier schon in althochdeutscher Zeit ein Lautwandel in Form einer Palatalisierung von [sk] zu [ʃ] vollzogen hatte, dieser sich aber im Schriftbild als <sk>, <sc> oder <sch> nicht niedergeschlagen hat, sodass heute der Frikativ mit dem letztgenannten Trigraph assoziiert wird (vgl. Bergmann/Moulin/Ruge 2011, 173-174).
Was diese Beispiele zeigen ist, dass die Sprachgemeinschaft – hier wäre wohl „Schreibgemeinschaft“ passender – über Möglichkeiten verfügt, Lücken im Ausgangs-Schriftsystem in Bezug auf einzelne Lauteinheiten auszugleichen und von dieser Möglichkeit auch Gebrauch macht.
5. Graphem-Phon(em)-Korrespondenz und deren Grenzen
Was haben historische Sprachbelege mit aktuellen Dialektbelegen zu tun? Die Gemeinsamkeit der beiden Belegarten liegt in der zeitlichen bzw. räumlichen Distanz zu der Person, durch die die Aufzeichnung erfolgte. In der Folge ist meist nicht bekannt, welche Aussprache dem jeweiligen Beleg zugrunde lag. Zum einen, weil die Graphem-Phon(em)-Beziehung sehr individuell ausgelegt werden kann und deshalb nicht eindeutig geklärt ist, zum anderen, weil das Zeichensystem des Alphabets nicht über die Möglichkeit verfügt, die einzelnen Lautwerte abzubilden. Für die historischen Sprachdenkmäler ergibt sich daraus die Schwierigkeit der Rekonstruktion des Lautwerts der einzelnen Zeichen bzw. des gesamten Wortes. Bei solch frühen Sprachbelegen kann eine Annäherung über heutige Lautwerte von Graphemen, Vergleich mit heutigen Dialekten, Heranziehung von Reimpaaren etc. erfolgen (vgl. Nerius 2003, 2465). In diesem Punkt unterscheidet sich rezentes Dialektmaterial, denn hier kann ein Abgleich mit Aufzeichnungen erfolgen, die meist direkt auch zu dem Zweck erhoben wurden, um auch für phonetische Fragestellungen herangezogen werden zu können.
Dennoch sind der sprachwissenschaftlichen Verwertbarkeit von schriftlich erfassten Dialekt-Belegen Grenzen gesetzt, was im Folgenden zwei Beispiele verdeutlichen sollen.
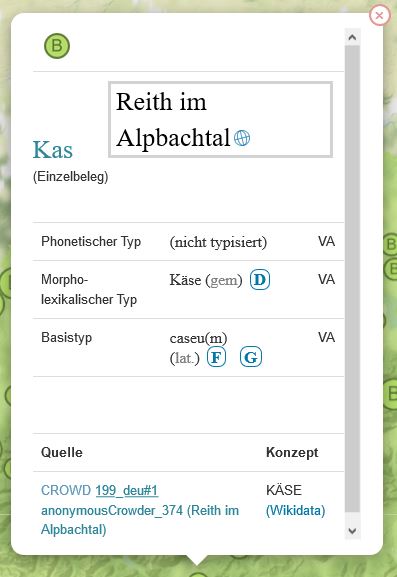
Crowd-Beleg zum Konzept KÄSE eines Informanten aus Reith im Alpbachtal (Tirol). Darstellung im Belegfenster der interaktiven Karte des Online-Portals von VerbaAlpina. (Interaktive Karte VerbaAlpina)
Der Beleg Kas lässt sich zweifelsfrei dem Worttypus Käse zuordnen, die Aussprache des Vokals selbst bleibt aber zuerst offen. Da dem Phonem /a/ im Standarddeutschen je nach Kontext [a] oder [ɑ] zugeordnet werden kann, ist eine Aussage über die Qualität des Stammvokals auf der Basis des Belegs nicht möglich, gleiches gilt für dessen Quantität. Für das Bairische ist diese Tatsache dahingehend von Bedeutung, als dass sie im Großteil der bairischen Varietäten beide Phonemstatus vorweisen, da es sich bei [a] um den Umlaut zu [ɑ] handelt, der wie im Standardeutschen zwar ebenfalls durch eine Verlagerung des Artikulationsortes gebildet wird, hier aber ohne eine Rundung auskommt (vgl. Kranzmayer 1956, 24).
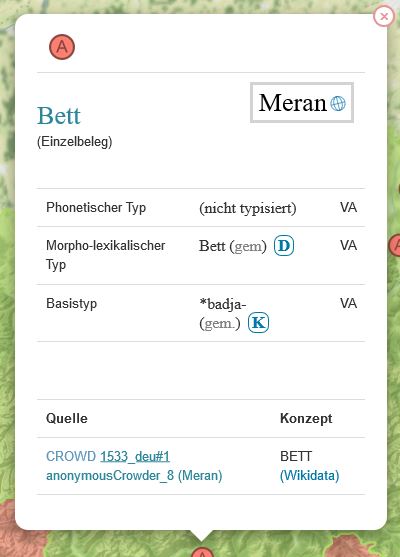
Crowdsourcing-Beleg zum Konzept BETT aus Meran (Südtirol). Darstellung im Belegfenster der interaktiven Karte des Online-Portals von VerbaAlpina. (Interaktive Karte VerbaAlpina)
Ähnliches gilt für den lautlichen Charakter im Beleg zu Bett, bei dem /e/ sowohl einem [e] als auch einem [ɛ] entsprechen kann.
Man tappt also gerade dort im Dunkeln, wo unterschiedliche Aussprachevarianten eines Phonems, repräsentiert durch ein Graphem, existieren.
6. Mehr als Lexik: Was Dialektbelege leisten können
Dessen ungeachtet ist man bei der Analyse von schriftlichen Dialekt-Belegen in Bezug auf die Aussprache nicht vollständig auf Spekulationen angewiesen. Mithilfe einiger vorangestellter Überlegungen lassen sich auch aus der Masse an Daten noch mehr Informationen ziehen, als man auf den ersten Blick vermuten würde.
Neben der alemannischen Form Anke ist die Wortform Butter die geläufige lexikalische Variante im deutschsprachigen Alpenraum für das gleich bezeichnete Konzept. Die folgende Tabelle zeigt eine Übersicht der verschiedenen Varianten zum standardsprachlichen Auslaut -er.
| Auslaut-Variante zu <er> in Butter | Anzahl (Anteil) |
| <a>, <o> | 99 (65 %) |
| <er> | 45 (29 %) |
| <r> | 9 (6 %) |
Tab. 1: Verschriftete Auslaut-Varianten der Crowdsourcing-Belege zum lexikalischen Typ Butter (Stand: 01.10.2020).
Wie bereits im Beispiel zu den Vokalen /a/ und /e/ in den oben genannten Beispielen Kas und Bett ist es notwendig, stets die Alphabetisierungssprache – hier das Standarddeutsche – im Hinterkopf zu behalten. Zuerst muss berücksichtig werden, dass wohl die Standardschreibung <Butter> bei den Informanten sehr präsent gewesen sein muss. Da die Aussprache des verschrifteten Auslauts <er> in den meisten Varietäten des Standarddeutschen einem zentralisierten [ɐ] entspricht, ist diese Interpretation zwar wahrscheinlich, gesichert ist sie jedoch nicht. Anders sieht es bei den Auslaut-Varianten aus, die durch einen Vokal dargestellt werden. Hier ist das ausdrückliche Bestreben zu erkennen, die Differenz zur Standardschreibung herzustellen. Ebenso ist die Verschriftung <r> für standardkonformes <er> zu werten, also etwa in der Form von Buttr. Mit dem Fehlen des <e> findet auch hier eine Abgrenzung zum standardnahen Auslaut <er> und damit zur Möglichkeit einer zentralisierten Aussprache statt.
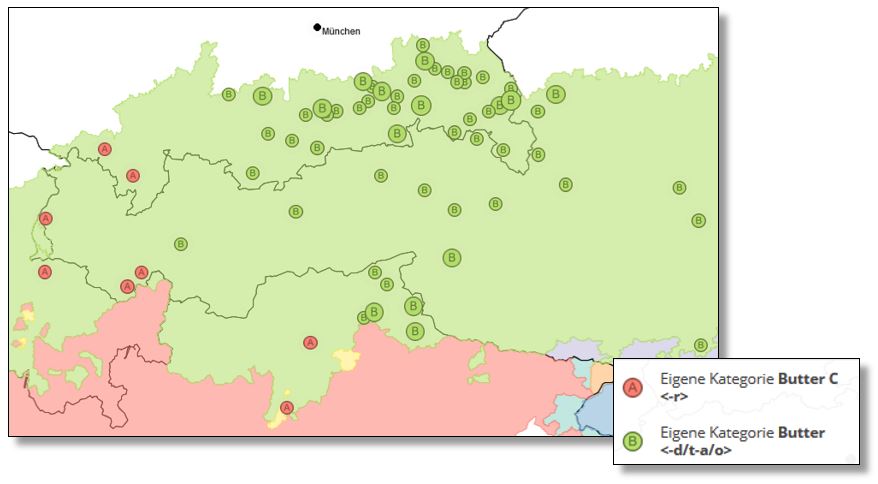
Crowdsourcing-Belege zum lexikalischen Typ Butter. Verteilung des Auslauts <a>/<o> und <r> für standarddeutsch <er>. (Interaktive Karte VerbaAlpina)
In der kartographischen Darstellung wird deutlich, dass die Wahl der graphemischen Niederschrift der Belege nicht zufällig ist. Hier zeichnen sich vor allem das alemannische Vorarlberg sowie Teile Südtirols ab, deren Dialekte die Vokalisierung von /r/ nach Vokal nicht in dem Maße aufweisen, wie es bei den Varietäten des restlichen Gebietes gegeben ist.
Eine nahezu anteilig gleiche Verteilung zeigen die Suffix-Grapheme zum Lexem melken:
| Auslaut-Variante zu <en> in melken | Anzahl (Anteil) |
| <a>, <e> | 80 (65 %) |
| <en> | 40 (29 %) |
| <n> | 4 (6 %) |
Tab. 1: Verschriftete Auslaut-Varianten der Crowdsourcing-Belege zum lexikalischen Typ melken (Stand: 01.10.2020).
Auch hier treffen sich Schreibvarianten mit vokalischem sowie konsonantischem Auslaut. Die standardnahe Schreibvariante <en> macht nur einen sehr geringen Anteil der gesamten Belege zu melken aus. Dass es sich hier ebenfalls um eine bewusste Schreibung handelt, das legt die Verteilung der Belege nahe.
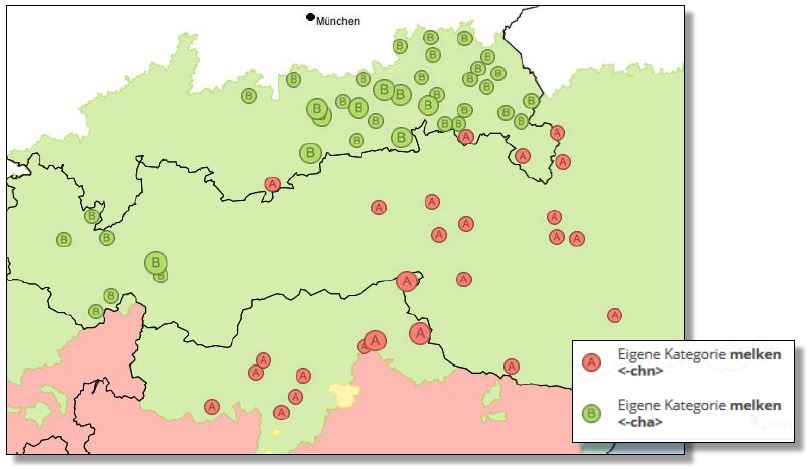
Crowdsourcing-Belege zum lexikalischen Typ melken. Verteilung des Auslauts <a>/<e> und <n> für standarddeutsch <er>. (Interaktive Karte VerbaAlpina)
Gut zu erkennen ist, dass sich die Variante mit vokalischer Endung auf Bayern und Voralberg beschränkt, während sich die Form mit erhaltenem Nasal auf den Südbairischen Sprachraum erstreckt, weshalb sie auf deutscher Seite nur im Berchtesgadener Land im Osten und in Mittenwald im Westen zu finden ist.
Auch wenn es um Phänomene wie die der /l/-Vokalisierung geht, sind die dialektalen Varianten zum Lexem melken eine dankbare Datengrundlage. Stellt man die diphthongischen den monophthongischen Varianten des Lexems.
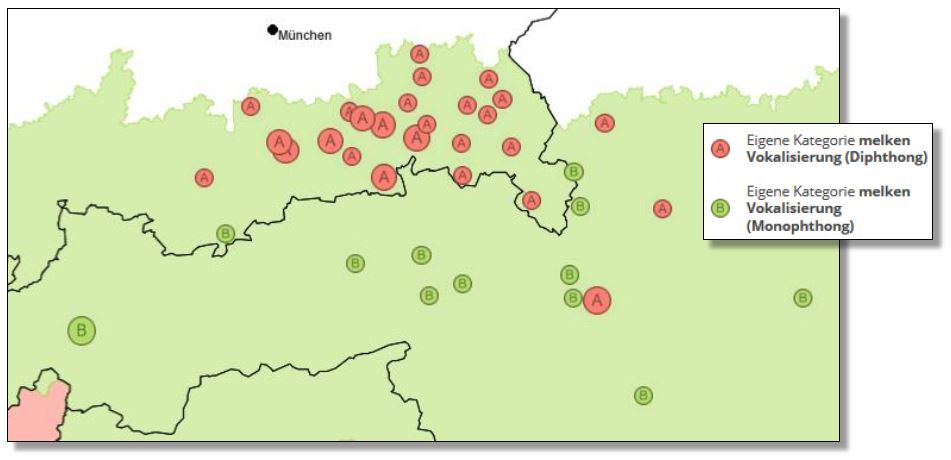
Crowdsourcing-Belege zum lexikalischen Typ melken. Verteilung diphthongischen und monophthongischen Vokalisierungen für <el> in melken. (Interaktive Karte VerbaAlpina)
Die diphthongischen Belege sind zwar auf österreichischer Seite vereinzelt im mittelbairisch-südbairischen Übergangsgebiet zu finden, in erster Linie handelt es sich aber um eine Variante, die sich – mit Ausnahme des südbairischen Ortes Mittenwald – auf Bayern beschränkt.
Ein letztes Beispiel das illustrieren soll, wie zuverlässig von Laien beigesteuertes Sprachmaterial beschaffen ist, zeigt das prominente Beispiel zum Konzept ALM. Dies ist in lexikalischer Hinsicht gerade in der Abgrenzung des alemannischen Worttyps Alp zum bairischen Alm interessant. Zugleich sollten sich die Gebiete mit /l/-Vokalisierung und erhaltenem Lateral sowie das Gebiet der sog. a-Verdumpfung, wie sie für die größten Teile des Bairischen üblich ist, ausfindig machen lassen können.
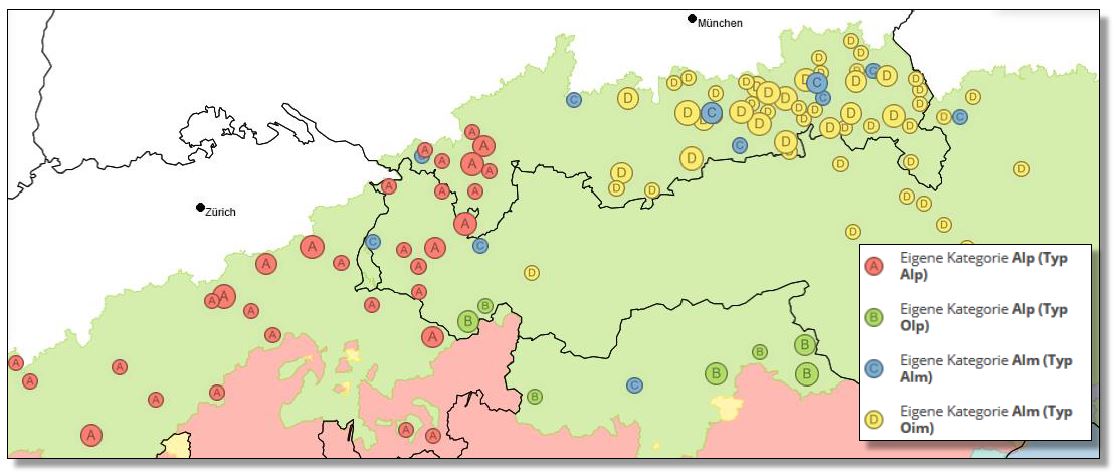
Crowdsourcing-Belege zum Konzept ALM. Verteilung der Belege der phonetischen Typen Alp und Olp des Wortyps Alp und von Alm und Oim des Worttyps Alm. (Interaktive Karte VerbaAlpina)
Die Verbreitung des phonetischen Typs Alp lässt deutlich den alemannischen Sprachraum hervortreten. Für die alemannisch geprägte Deutschschweiz stellt sie die alleinige Form dar, hingegen sind im österreichischen Vorarlberg und im bayerischen Allgäu vereinzelt auch Belege des phonetischen Typs Alm zu finden. Dies ist kein Zufall, denn der Rest Österreichs sowie der Großteil des bayerischen Untersuchungsgebietes ist mehrheitlich bairisch geprägt, während dies in der Deutschschweiz nicht zutrifft. Eine Alp-Variante ist auch in den Dialekten Tirols und Südtirols als Olp anzutreffen. Dass diese Variante im Südbairischen Verbreitung findet, lässt sich auch durch Toponyme untermauern, wie der Alpspitze im Wettersteingebirge oder dem Ort Alpbach im Tiroler Unterland bei Kufstein. Zugleich zeigt der Typ Olp mit der Verdumpfung von mhd. <a> hingegen ein typisch bairisches Merkmal. Zu guter Letzt machen die Belege mit durchgesetzter /l/-Vokalisierung im Mittelbairischen deutlich, dass sich die Informanten dieser Lautform bewusst sind und diese in gleicher Weise verschriften.
7. Fazit
Während traditionelle Erhebungen areal als auch in diachroner Hinsicht Lücken aufweisen, kann Crowdsourcing als komplementäres Verfahren zur Datenerhebung eingesetzt werden und diesem Defizit begegnen. Somit können mittels Crowdsourcing diese blinden Flecken im Raum ergänzt werden; zugleich bilden diese Belege den aktuellen Sprachstand ab. Darüber hinaus ist diese Erhebungsmethode im Vergleich zur klassischen Feldforschung wesentlich zeit- und kostengünstiger. Demgegenüber weist dieses Verfahren jedoch auch eine Reihe von Nachteilen auf. Allen voran ist hier die schlechte Kontrollierbarkeit bezogen auf die Resonanz der Maßnahmen, die die Crowder zur Teilnahme anregen sollen, zu nennen. Zudem gleicht die Diskrepanz zwischen einer verwertbaren Basis soziolinguistischer Metadaten des Informanten und einer ausreichenden Anzahl an Belegen einem Drahtseilakt, da man Gefahr läuft, den möglichen Crowder durch zu viele Fragen zu seiner Person bereits im Vorfeld abzuschrecken.
Dass zudem diese Sprachdaten zu weit mehr als zum Befund lexikalischer Varianz dienen können, zeigt ein differenzierter Blick auf die Belege. So ist die Annahme, dass sich varietätenspezifische Merkmale aufgrund der starken Präsenz schriftsprachlicher Standardvarianten kaum bis gar nicht in den laienverschrifteten Belegen wiederfinden, widerlegbar. So können zwar standardnahe Graphien nicht per se als Repräsentation von Mündlichkeit gelesen werden, weichen sie aber geringfügig von der Standardgraphie ab, so darf es als eine bewusste Handlung des Informanten interpretiert werden. Hier ist beispielsweise die vokalische versus der nasalen/liquiden Auslautvariante zu standardsprachlich <-en>/<-er> oder auch die Umsetzung der unterschiedlichen Vokalisierungsformen zu /l/ nach Vokal zu nennen. Auch was die Verschriftung von Lautsegementen betrifft, zu denen das Standardalphabet kein Graphem bereithält, verdeutlichen die Crowdbelege die kreativen Lösungsansätze. So findet standardsprachliches <ir>/<er>, dass in der Standardaussprache meist als /ɪɐ/ bzw. /ɛɐ/ auftritt, sich in indirekt erhobenen Dialektbelegen selbst an Stellen wieder, deren Worttypen kein /r/ aufweisen.
Bibliographie
- ALF = ALF: Atlas Linguistique de la France, (01.10.2020) (Link).
- American Psychological Asscociation 2020 = American Psychological Asscociation (2020): primacy effect, in: APA Dictionary of Psychology (Link).
- American Psychological Asscociation 2020b = American Psychological Asscociation (2020): recency effect, in: APA Dictionary of Psychology (Link).
- Bergmann/Moulin/Ruge 2011 = Bergmann, Rolf / Moulin, Claudine / Ruge, Nikolaus (82011): Alt- und Mittelhochdeutsch, Göttingen, Vandenhoeck & Ruprecht, 56.
- Besch/Betten/Reichmann/Sonderegger 2003b = Besch, Werner / Betten, Anne / Reichmann, Oskar / Sonderegger, Stefan (Hrsgg.) (22003): Sprachgeschichte. Ein Handbuch zur Geschichte der deutschen Sprache und ihrer Erforschung., vol. 3, Berlin/New York, De Gruyter.
- Eichhoff 1982 = Eichhoff, Jürgen (1982): Erhebung von Sprachdaten durch schriftliche Befragung, in: Besch, Werner et. al. (Hrsg.), Dialektologie. Ein Handbuch zur deutschen und allgemeinen Dialektforschung. , vol. 1, Berlin/New York, Walter de Gruyter (Handbücher zur Sprach- und Kommunikationswissenschaft Band 1.1), 549–554.
- Juska-Bacher/Biemann/Quasthoff 2014 = Juska-Bacher, Britta / Biemann, Chris / Quasthoff, Uwe (2014): Webbasierte linguistische Forschung: Möglichkeiten und Begrenzungen beim Umgang mit Massendaten., in: Linguistik Online 61 (4), 7-29 (Link).
- Kleiner 2019 = Kleiner, Stefan (2019): Realisierung von /ɪ/, in: Atlas zur Aussprache des deutschen Gebrauchsstandards (AADG), Mannheim, Leibniz-Institut für Deutsche Sprache (Link).
- Kranzmayer 1956 = Kranzmayer, Eberhard (1956): Historische Lautgeographie des gesamtbairischen Dialektraumes, Wien, Böhlau, 143.
- Krefeld 2019g = Krefeld, Thomas (2019): Der Sprach- und Sachatlas Italiens und der Südschweiz (AIS) – ein Prototyp. Version 4 (10.04.2019, 15:25). Lehre in den Digital Humanities. (Link).
- Kunzmann/Mutter 2020 = Kunzmann, Markus / Mutter, Christina (2020): Dialektdatenerhebung neu gedacht: Vom Nutzen des Netztes für die Sprachwissenschaft., in: IDS Sprachreport 2, Mannheim, Leibniz-Institut für Deutsche Sprache, 32-37 (Link).
- Lücke 2019 = Lücke, Stephan (2019): Einführung in die Geolinguistik (ITG/slu). Version 1 (13.01.2019, 09:44). Lehre in den Digital Humanities. (Link).
- Nerius 2003 = Nerius, Dieter (2003): Graphematische Entwicklungstendenzen in der Geschichte des Deutschen, in: Besch, Werner / Betten, Anne / Reichmann, Oskar / Sonderegger, Stefan (Hrsg.): Sprachgeschichte. Ein Handbuch zur Geschichte der deutschen Sprache und ihrer Erforschung, Berlin/New York, De Gruyter., 2461-2472.
- REDE = REDE: regionalsprache.de, (01.10.2020) (Link).
- Schmid 2017 = Schmid, Hans Ulrich (32017): Einführung in die deutsche Sprachgeschichte, Stuttgart, J. B. Metzler, 314.
- Seiler 2010 = Seiler, Guido (2010): Investigating language in space: Questionnaire and interview. , in: Auer, Peter / Schmidt, Jürgen Erich (Hrsgg.), Language and Space. An International Handbook of Linguistic Variation., vol. 1, Berlin/New York, Mouton De Gruyter (Handbooks of Linguistics and Communication Science 30.1), 512–527.
- SyHD = SyHD: Syntax hessischer Dialekte, (30.09.20) (Link).